肿瘤基因检测数据分析与解读全流程简要介绍
大家好,我是阿尔的太阳
随着测序成本的下降
和人类医药研究对肿瘤的不断进步
会有越来越多的普通肿瘤患者告别盲目的治疗
并大大受益于肿瘤基因检测
无论是取组织测序
还是无创液态活检去检测血液中的ctDNA
数据下机以后需要专业的生信部门进行分析
本文将要对数据分析与解读全流程进行简要介绍
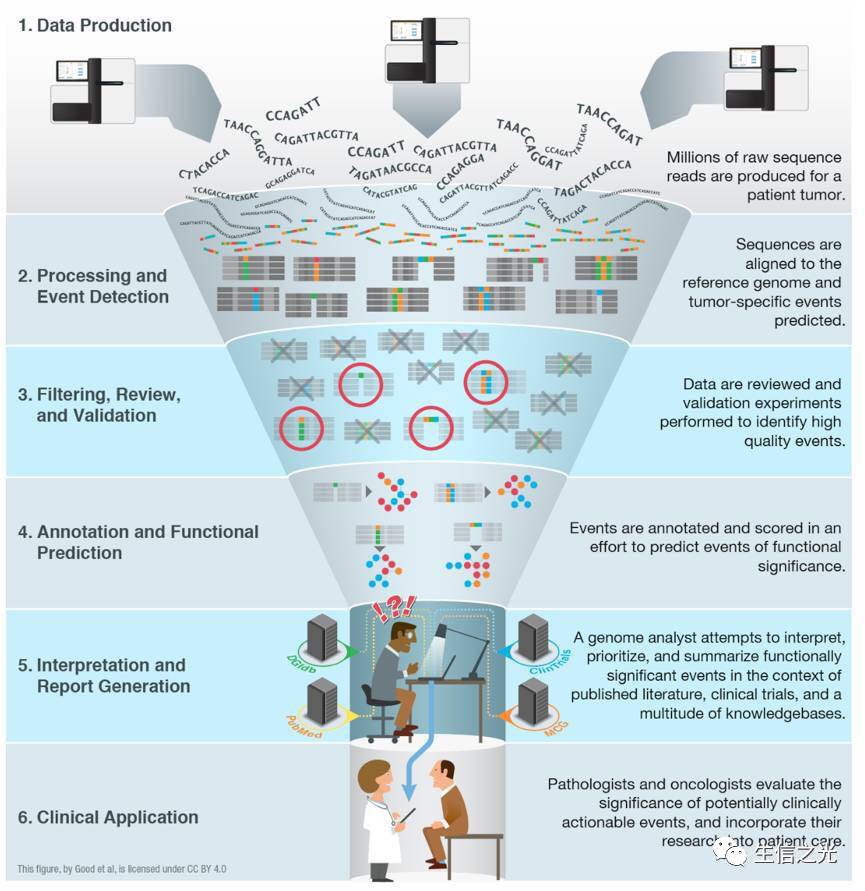
肿瘤基因检测数据分析与解读全流程大概分为以下几个步骤
1.初步分析
2.后续过滤
3.下游解读
这一个整体过程中都需要进行严格的系统性的质量控制
因为医疗应用关乎生命健康
1.初步分析
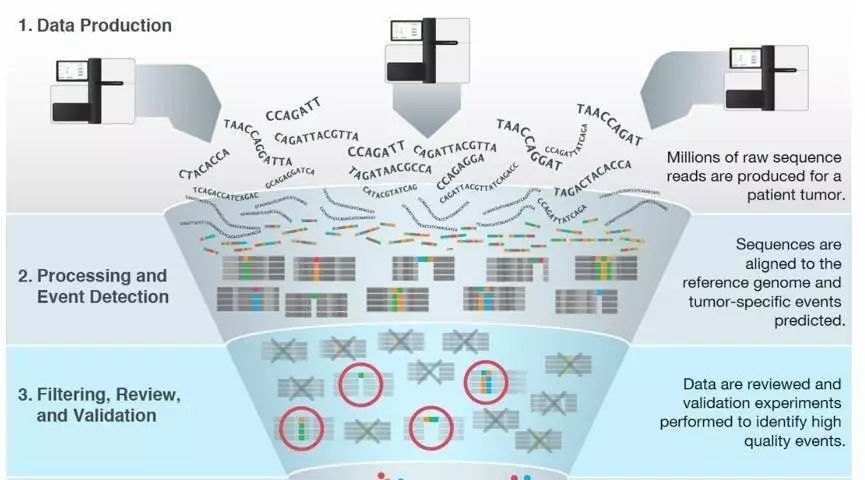
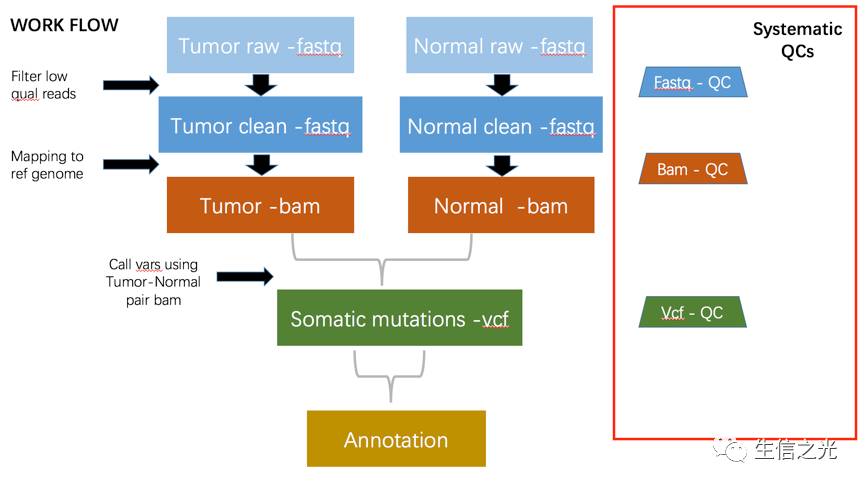
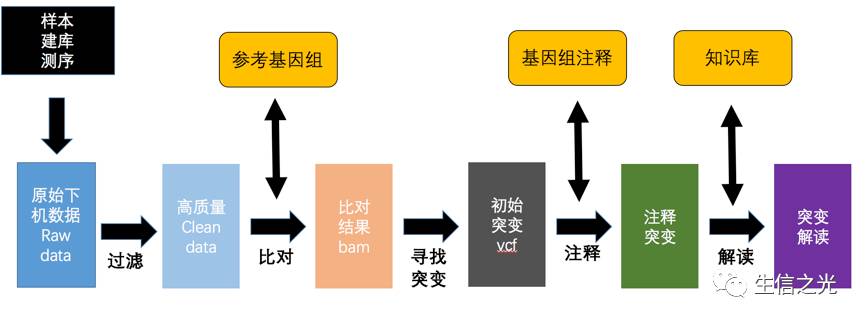
NGS数据初步分析基本是四个数据流 :fq-bam-vcf-anno
fq 是原始的下机数据
bam 是比对的情况
vcf 存贮着原始突变信息
anno 则是注释的信息

fastq文件目前大部分是 illumina机器的数据,肿瘤基因检测涉及到应用的话大部分都是 drugable position in the ref genome 就是已经有了明确目标的基因位点了知道在参考基因组的哪个位置,因此大部分都是 panel [目的捕获测序],也有WES全外显子测序,WGS比较少,毕竟成本太高了,数据不是一个量级。
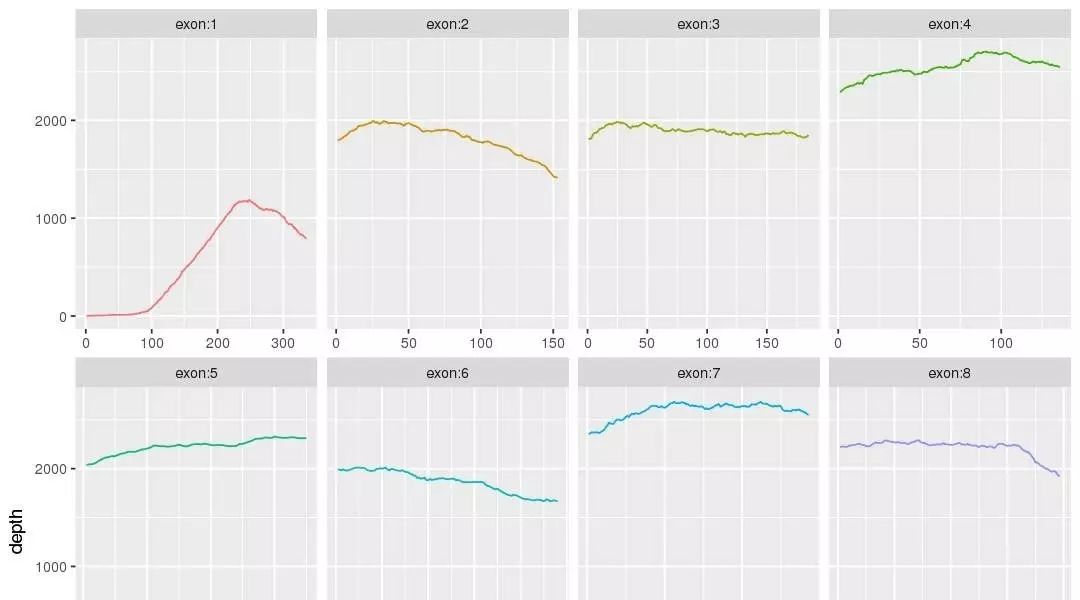
fq会被过滤掉低质量的reads得到 clean data ,后续会使用比对软件比如BWA比对到参考基因组,然后经过去除PCR重复,得到可以用于下一个步骤的bam文件
bam是二进制的Sam文件里面存储着比对的情况,经过突变寻找软件比如GATK会找到突变,注意样本不一定有配对就是有可能只是肿瘤的单样本
突变vcf文件经过注释软件注释以后,会知道其具体在参考基因组哪个位置,有没有在某个数据库中出现过,到这里,初步分析就已经完成了
2.后续过滤
这一步骤就非常重要,比如过滤掉一些低质量的不可信的突变以及一些和基线Baseline 数据库相比较的很可能是正常突变的基因突变。
最终得到很少的高可信的SOMATIC MUTATION。


3.下游解读
这个步骤会涉及到很多的数据库和医学知识,对突变进行解读
比如FDA NCCN ClinicalTrials Drugbank Clvic 等等
最终给予患者和医生一个参考决策
指导具体使用哪种药物会有更好的效果
除了FDA批准的成熟上市药物,还可以尝试临床试验的新药
最后用一张图片来做总结
这一个整体数据分析过程中都需要进行严格的系统性的质量控制
因为医疗应用关乎生命健康
以上便是肿瘤数据分析与解读全流程的简要介绍