细菌基因组测序常见问题及结果解读FAQ
原文主要参考自诺禾致源公众号,作者杨萍,本人对文章内容修改,并添加自己的理解。
单菌基因组测序常见问题
测序碱基准确率是什么意思,具体的计算方法是什么?
碱基测序的质量值Q是准确度(P)的一种格式转换,是为了方便使用一个字符表示非常复杂的准确度,占用最小空间;转换公式为P=1-10^(-Q/10),如Q=30/20/10的准确度分别为99.9%,99%,90%。
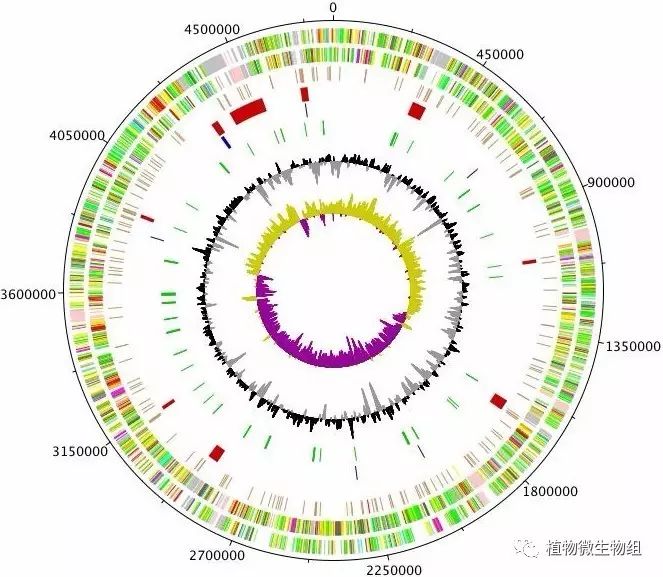
细菌基因组的组装结果中,N50和N90的具体含义,以及如何计算?
它们是基因组组装中常用的组装指标,要知道是越大越好。大于N50长度的序列占基因组总长的50%,大于N90长度的序列占基因组总长的90%。
具体计算方法:将所有拼接序列按照长度从大到小排列,找到TopNr 序列总长度刚好大于基因组总长度的50%(90%)位置,则该序列的长度定义为N50(N90);该数值反映了基因组50%(90%)以上的区域,都能被该数值以上长度的序列覆盖,同时体现了组装质量对于后续数据分析的质量贡献。
在有杂菌污染的情况下,为什么得不到好的组装结果呢?
不同物种会有非常多的同源序列,高度相似序列会对组装软件产生干扰,而软件为保证组装的准确性,只能将可疑的部分切断成不同的碎片序列
在完成图中,为什么有的质粒可以成环,而有的却不能?
不同质粒拷贝数和被测到的深度不同
在真菌基因组测序时,为什么注释的基因数量这么少?
真菌全基因组数据库太少,连ITS注释都很少,这几年正在快速发展
次级代谢产物基因簇注释分析中,为什么会出现没有预测到PKS(聚酮合酶)和NRPS(非核糖体肽合成酶)结构的情况呢?
在次级代谢产物基因簇注释分析中,分两步进行分析:
-
首先,我们先对是否存在PKS(聚酮合酶)和NRPS(非核糖体肽合成酶)进行预测;
-
其次,根据目前软件训练集中的基因簇的结构进行预测,如果训练集中的基因簇中有匹配的结构就会被预测出来,否则就会无法预测到;
-
简而言之,如果无法预测到PKS(聚酮合酶)和NRPS(非核糖体肽合成酶)结构,可能是由于样本本身就不存在这两种酶,或者是这两种酶的结构与训练集中的结构不匹配。
根据文献中的经验,常预测出的代谢物基因簇,按出现频率分别为: nrps,
nonribosomal peptide synthetase; t1pks, type I PKS; t3pks, type III PKS; t2pks, type II PKS; hserlactone, homoserine lactone; transatpks, trans-AT PKS (Hadjithomas2015, Fig.2:)
如果关注的基因没有被注释出来,是什么原因呢?
-
可能该基因在拼接时没有被成功拼接;
-
该基因在目标基因组上可能压根不存在;
-
在注释的数据库里还没有该基因的相关记录,所以无法被参考注释出来;
-
研究的具体株菌中,可能根本不存在这个基因,还需要进一步确定该菌株中是否真的含有该基因。
Reference
-
Hadjithomas, M., et al. (2017). “IMG-ABC: new features for bacterial secondary metabolism analysis and targeted biosynthetic gene cluster discovery in thousands of microbial genomes.” Nucleic Acids Res 45(D1): D560-D565.
-
Hadjithomas, M., et al. (2015). “IMG-ABC: A Knowledge Base To Fuel Discovery of Biosynthetic Gene Clusters and Novel Secondary Metabolites.” MBio 6(4): e00932.